

A Distributed Code Execution Engine with Scala and Pekko
by Anzori (Nika) Ghurtchumelia
1. Introduction
In this article we will attempt to build the remote code execution engine - the backend platform for websites such as Hackerrank, LeetCode and others.
For such a platform, the basic usage flow is:
- Client sends code
- Backend runs it and responds with output
Sounds simple, right? Right?…
Can you imagine how many things can go wrong here? The possibilities for failure are endless! However, we should address at least some of them.
We can probably write a separate blog post about the security, scalability, extensibility and a few other compulsory properties to make it production ready.
The goal isn’t to build the best one, nor it is to compete with the existing ones.
Put simply, the goal of this project is to get familiar with Apache Pekko (the open source version of Akka) and its modules such as pekko-http, pekko-stream, pekko-cluster and a few interesting concepts around actor model concurrency, such as:
- cluster nodes and formation
- cluster aware routers
- remote worker actors
- actor lifecycle and hierarchy
- actor supervision strategies
- actor location transparency
- message serialization
- and so on…
Let’s get started then, shall we?
Hey, it’s Daniel here. Apache Pekko is great, and Nika has done a great job showcasing its features in a compact project we can explore exhaustively in this article. If you need to get started with Pekko, I’ve covered Pekko (and Akka) in a comprehensive bundle of courses about Akka/Pekko Actors, Akka/Pekko Streams, and Akka/Pekko HTTP, all of which are used in this article. Check them out if you’re interested.
2. Project Structure
To make the best of this article, I recommend checking out the project on GitHub and following the code while reading this article, as many things will make sense along the way.
We will use Scala 3.4.1, sbt 1.9.9, docker, pekko and its modules to complete our project.
The initial project skeleton looks like the following:
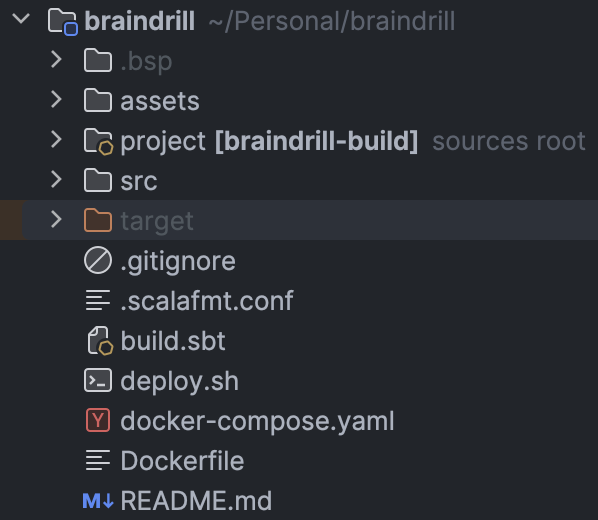
assetsfolder contains images mainly for setting up goodREADME.mdsrccontains production and test codetargetwill store the compiled.jarfile that we will run later.gitignoreforgitto ignore some changes.scalafmt.conffor formatting Scala codebuild.sbtfor defining build steps, external library dependencies and so ondeploy.shis a useful script for deploying the project locally within usingdocker-composedocker-compose.yamlfor defining apps, their configuration and propertiesDockerfileblueprint for running the app inside containerREADME.mdinstructions for setting up the project locally
Let’s start with build.sbt:
ThisBuild / scalaVersion := "3.4.1"
val PekkoVersion = "1.0.2"
val PekkoHttpVersion = "1.0.1"
val PekkoManagementVersion = "1.0.0"
assembly / assemblyMergeStrategy := {
case PathList("META-INF", "versions", "9", "module-info.class") => MergeStrategy.discard
case PathList("module-info.class") => MergeStrategy.discard
case x =>
val oldStrategy = (assembly / assemblyMergeStrategy).value
oldStrategy(x)
}
libraryDependencies ++= Seq(
"org.apache.pekko" %% "pekko-actor-typed" % PekkoVersion,
"org.apache.pekko" %% "pekko-stream" % PekkoVersion,
"org.apache.pekko" %% "pekko-http" % PekkoHttpVersion,
"org.apache.pekko" %% "pekko-cluster-typed" % PekkoVersion,
"org.apache.pekko" %% "pekko-serialization-jackson" % PekkoVersion,
"ch.qos.logback" % "logback-classic" % "1.5.6"
)
lazy val root = (project in file("."))
.settings(
name := "braindrill",
assembly / assemblyJarName := "braindrill.jar",
assembly / mainClass := Some("BrainDrill")
)
As shown:
- we mainly use
pekkolibraries for main work andlogback-classicfor logging rootdefinition which defines thename,assemblyJarNameandmainClass- all of which is used by
sbt assemblyto turn our code intobraindrill.jar
Also, we configure the assemblyMergeStrategy for sbt-assembly to handle file conflicts when creating a JAR. It defines how to merge files from different JARs:
Discard Specific Files:
META-INF/versions/9/module-info.classmodule-info.class
Default Strategy:
- For all other files, use the default merge strategy.
The main idea here is to avoid conflicts with Java 9 module system files and ensure smooth merging of other files.
and a one line definition in project/plugins.sbt:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "2.1.1") // SBT plugin for using assembly command
3. Project Architecture
After a few iterations I came up with the architecture that can be horizontally scaled, if required. Ideally, such projects should be scaled easily as long as the load is increased.
For that we use tools such as Kubernetes or other container orchestration platforms. To make local development and deployment simpler we’ll be using Docker containers. More precisely we’ll be using docker-compose to run a few containers together so that they form the cluster.
docker-compose doesn’t support scalability out of the box because it’s static, it means that we can’t magically add new worker nodes to the running system. Again, for that we’d use Kubernetes, but it is out of the scope of this project.
We have a master node and its role is to be the task distributor among worker nodes.
http is exposed on master node, acting as a gateway to outside world.
3.1 Architecture Diagram
Let’s explain step by step what happens during code execution:
- User sends request at POST
http://localhost/pythonwithpythoncode attached to request body httpprocesses the request- randomly chosen
load balancersends message toworker routeron some node worker routersends message toworkerwhich starts execution- … skipping lots of details …
workerresponds toload balanceronce the code is executedload balancerforwards message tohttpand user receives the output
3.2 Docker runtime
There are a few options to my knowledge for executing the submitted code with the help of docker containers. All I can do is redirect you to the great StackOverflow post which expands on this issue.
Long story short, I decided to go with DooD - Docker out of Docker.
DooD Uses the host’s Docker daemon by mounting /var/run/docker.sock into the container.
It means that if the host machine has the docker engine installed on it:
- it can start container
Ausing/var/run/docker.sockwhich listens for commands - it can start “sibling” container
Bby executing commands such asdocker run ...from containerA, using/var/run/docker.sock
In our domain terms:
- container
Awill beworker-1container, which will be starting sibling containers - sibling containers will be short-lived, limited (CPU, RAM, timeout) containers which run
python,javaand such processes
Advantages of DooD:
- Efficient: Direct use of host resources.
- Simple: No extra Docker daemons.
- Fast: No nested virtualization overhead.
- Resource-efficient: Shared daemon optimizes resource use.
Disadvantages:
- Security risk: Access to host Docker daemon.
- Less isolation: Shared daemon.
- Overhead: Starting/Stopping containers all the time
3.3 docker-compose
Since we want to run a pekko cluster we could use docker-compose and its declarative definitions for cluster components such as master and worker nodes, with shared volume, image names, ports mappings, environment variables and so on.
This is how docker-compose.yaml could look like in the root directory of our project:
version: '3'
services:
master:
image: braindrill:latest
build:
context: .
dockerfile: Dockerfile
container_name: 'master'
tty: true
stdin_open: true
ports:
- '1600:1600'
- '8080:8080'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- engine:/data
working_dir: /app
environment:
CLUSTER_IP: 'master'
CLUSTER_PORT: '1600'
CLUSTER_ROLE: 'master'
SEED_IP: 'master'
worker-1:
image: braindrill:latest
build:
context: .
dockerfile: Dockerfile
tty: true
stdin_open: true
ports:
- '17350:17350'
security_opt:
- 'seccomp=unconfined'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- engine:/data
working_dir: /app
environment:
CLUSTER_IP: 'worker-1'
CLUSTER_PORT: '17350'
CLUSTER_ROLE: 'worker'
SEED_IP: 'master'
SEED_PORT: '1600'
worker-2:
image: braindrill:latest
build:
context: .
dockerfile: Dockerfile
tty: true
stdin_open: true
ports:
- '17351:17351'
security_opt:
- 'seccomp=unconfined'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- engine:/data
working_dir: /app
environment:
CLUSTER_IP: 'worker-2'
CLUSTER_PORT: '17351'
CLUSTER_ROLE: 'worker'
SEED_IP: 'master'
SEED_PORT: '1600'
worker-3:
image: braindrill:latest
build:
context: .
dockerfile: Dockerfile
tty: true
stdin_open: true
ports:
- '17352:17352'
security_opt:
- 'seccomp=unconfined'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- engine:/data
working_dir: /app
environment:
CLUSTER_IP: 'worker-3'
CLUSTER_PORT: '17352'
CLUSTER_ROLE: 'worker'
SEED_IP: 'master'
SEED_PORT: '1600'
volumes:
engine:
external: true
This docker-compose.yaml file sets up a Pekko cluster with one master and three worker services.
Key points include:
- Version: Uses Docker Compose version 3.
- Services: Defines four services -
master,worker-1,worker-2, andworker-3.
Master:
- Image: Uses
braindrill:latestand builds from the Dockerfile in the current context.braindrillimage will be built using a specialDockerfiledefinition which will be covered later. For better automation, we could also write a deployment shell script that automates all those details. - Container Name:
master- in Pekko terms - master node - Ports: Maps
1600:1600and8080:8080 - Volumes: Mounts Docker socket for
DooDandenginevolume for sharing temporary files (e.gpython123.py,Program123.java) where user code will be written. - Environment Variables: Sets cluster details (
CLUSTER_IP,CLUSTER_PORT,CLUSTER_ROLE,SEED_IP).
Workers:
- Image: Uses
braindrill:latestand builds from the Dockerfile in the current context. - Ports: Each worker maps a unique port (
17350,17351,17352). - Security: Disables default security profiles (
seccomp=unconfined). - Volumes: Mounts Docker socket for
DooDandenginevolume for sharing temporary files where user code will be written. - Environment Variables: Sets cluster and seed details for each worker.
Common Settings:
- TTY and stdin_open: Enabled for interactive use.
- Working Directory:
/app.
Volumes:
- Engine: An external volume named
enginewhich is necessary to share temporary program files that will be later executed.
3.4 Dockerfile
Dockerfile is a declarative file for building a docker image.
# Use an official OpenJDK runtime as a parent image
FROM hseeberger/scala-sbt:17.0.2_1.6.2_3.1.1
# Update the repository sources list and install required packages
RUN apt-get update && \
apt-get install -y \
docker.io # docker.io needed to run `docker` commands from the container itself
# Set the working directory to /tmp
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Build the Scala project
RUN sbt clean assembly
# Run application when the container launches
ENTRYPOINT ["java", "-jar", "target/scala-3.4.1/braindrill.jar"]
3.5 Local deployment shell script
Deployment shell script is a handy tool that enables us to run the project locally with a single command.
The goal is to automate the following:
- creating an image -
braindrill - creating a volume -
engine - pulling programming language runtime images (
java,pythonand others) - redeploying the nodes with the new version of
braindrillimage if required
So, it could look like the following:
#!/bin/bash
# Function to print help message
print_help() {
echo "Usage: $0 [rebuild]"
echo " rebuild Add --build flag to docker-compose up"
}
# Check for the "rebuild" argument
DOCKER_COMPOSE_CMD="docker-compose up"
if [ "$1" == "rebuild" ]; then
DOCKER_COMPOSE_CMD="docker-compose up --build"
elif [ -n "$1" ]; then
print_help
exit 1
fi
# Create Docker volume if it doesn't exist
VOLUME_NAME="engine"
if docker volume inspect "$VOLUME_NAME" > /dev/null 2>&1; then
echo "Docker volume '$VOLUME_NAME' already exists."
else
echo "Creating Docker volume '$VOLUME_NAME'."
docker volume create "$VOLUME_NAME"
fi
# Docker images to be pulled
DOCKER_IMAGES=(
"openjdk:17"
"python"
"node"
"ruby"
"perl"
"php"
)
# Pull Docker images in parallel if they don't already exist
for IMAGE in "${DOCKER_IMAGES[@]}"; do
if docker image inspect "$IMAGE" > /dev/null 2>&1; then
echo "Docker image '$IMAGE' already exists."
else
echo "Pulling Docker image '$IMAGE' in the background."
docker pull "$IMAGE" &
fi
done
# Wait for all background jobs to complete
wait
echo "All Docker images pulled."
echo "Running command: $DOCKER_COMPOSE_CMD"
$DOCKER_COMPOSE_CMD
This deployment shell script (deploy.sh) sets up a Docker environment and optionally rebuilds the Docker images. Key points include:
- Help Function:
- Provides usage instructions for the script.
- Rebuild Argument Check:
- If “rebuild” is passed as an argument, the script adds
--buildto thedocker-compose upcommand. - If an unrecognized argument is passed, it prints the help message and exits.
- If “rebuild” is passed as an argument, the script adds
- Docker Volume Management:
- Checks if a Docker volume named
engineexists. - If not, it creates the volume which is necessary for worker containers to access temporary files to be executed later
- Checks if a Docker volume named
- Docker Image Management:
- Defines a list of Docker images to be pulled (
openjdk:17,python,node,ruby,perl,php). - Checks if each image exists locally and pulls it in the background if it does not.
- Defines a list of Docker images to be pulled (
- Parallel Image Pulling:
- Uses background jobs to pull Docker images simultaneously for efficiency.
- Waits for all background jobs to complete.
- Run Docker Compose:
- Executes the
docker-compose upcommand, with or without the--buildflag based on the initial argument.
- Executes the
4. Configuration
Before writing any code let’s check resources/application.conf which is defined in HOCON format:
pekko {
actor {
provider = cluster
serialization-bindings {
"serialization.CborSerializable" = jackson-cbor
}
}
http {
host-connection-pool {
max-open-requests = 256
}
}
remote {
artery {
canonical.hostname = ${clustering.ip}
canonical.port = ${clustering.port}
large-message-destinations=[
"/temp/load-balancer-*"
]
}
}
cluster {
seed-nodes = [
"pekko://"${clustering.cluster.name}"@"${clustering.seed-ip}":"${clustering.seed-port}
]
roles = [${clustering.role}]
downing-provider-class = "org.apache.pekko.cluster.sbr.SplitBrainResolverProvider"
}
}
http {
port = 8080
host = "0.0.0.0"
}
clustering {
ip = "127.0.0.1"
ip = ${?CLUSTER_IP}
port = 1600
port = ${?CLUSTER_PORT}
role = ${?CLUSTER_ROLE}
seed-ip = "127.0.0.1"
seed-ip = ${?CLUSTER_IP}
seed-ip = ${?SEED_IP}
seed-port = 1600
seed-port = ${?SEED_PORT}
cluster.name = ClusterSystem
}
This file configures various settings for the Pekko application, including actor system properties, HTTP settings, remote communication, and clustering parameters:
Pekko Actor System Configuration
provider = cluster: This setting specifies that the actor system will use clustering capabilities.serialization-bindings: This section defines serialization bindings for specific classes. Here, any class implementingserialization.CborSerializablewill be serialized using thejackson-cborserializer.
HTTP Configuration
host-connection-pool.max-open-requests: This setting specifies the maximum number of open requests in the HTTP host connection pool. It is set to 256.
Remote Communication Configuration
remote.artery: This section configures the Artery transport (a remoting mechanism in Pekko).canonical.hostname: This sets the hostname for the actor system, which is derived fromclustering.ip.canonical.port: This sets the port for the actor system, which is derived fromclustering.port.large-message-destinations: Specifies destinations for large messages. In this case, any destination matching the pattern/temp/load-balancer-*will be treated as a large message destination.
Cluster Configuration
seed-nodes: Defines the initial contact points for the cluster, using placeholders for cluster name, seed IP, and seed port.roles: Specifies the roles of the cluster node, derived from clustering.role.downing-provider-class: Specifies the class for handling split-brain scenarios. Here, it’s set toSplitBrainResolverProvider.
Http Server Configuration
http.port: Sets the HTTP server port to 8080.http.host: Sets the HTTP server host to 0.0.0.0, meaning it will bind to all available network interfaces.
Clustering Variables
ip: Default IP address for clustering is 127.0.0.1. It can be overridden by the environment variableCLUSTER_IP.port: Default port for clustering is 1600. It can be overridden by the environment variableCLUSTER_PORT.role: Role of the cluster node, which can be set using the environment variableCLUSTER_ROLE.seed-ip: Default seed IP address is 127.0.0.1. It can be overridden byCLUSTER_IPorSEED_IP.seed-port: Default seed port is 1600. It can be overridden by the environment variableSEED_PORT.cluster.name: Name of the cluster, set toClusterSystem.
This configuration file is designed to be flexible, allowing for environment-specific overrides while providing sensible defaults, it plays crucial role with running the pekko cluster within the containers.
4.1 transformation.conf
The project also requires a special configuration for capturing properties for domain objects such as worker, load-balancer and so on.
include "application"
transformation {
workers-per-node = 32
load-balancer = 3
}
Here, it means that each node will have 32 worker actors and master node will have 3 load balancer actors. In the real world, choosing those numbers would depend on multiple variables that must be collected and analyzed in production. In my opinion, those numbers are optimized based on empirical evidence rather than theoretical results.
4.2 Serialization
Since we’re building a cluster we need to keep in mind that actor messages must be serialized over wire. It means that messages could be sent from JVM to JVM which requires enabling the serialization protocol.
For that we need a simple trait definition under serialization package, as we’ve already defined in configuration.
package serialization
// just a marker trait to tell pekko to serialize messages into CBOR using Jackson for sending over the network
trait CborSerializable
5. Actors
In this section we will write the code for actors that will do the real job - code execution.
Those actors will be:
Worker: actor that initiates code executionFileHandler: child actor ofWorkerwhich prepares the temporary file before executing itCodeExecutor: child actor ofFileHandlerwhich starts the process and collects output
Now, time to dig into the details.
5.1 Worker
Let’s quickly evaluate what we would expect from Worker.
Worker actor will live on worker node and will be reacting to StartExecution message.
Also, during runtime, it must be aware of which languages are supported, so that it quickly replies something like ExecutionFailed response with the message "unsupported language".
For successful case, we could have ExecutionSucceeded message that will be forwarded back to the original sender.
How about making Worker actor work within a cluster? We said earlier that the Worker actor will be expecting messages from master node, here enters remoting and other good stuff.
Somehow, Worker actor must be discovered within pekko cluster so that messages can be routed to it, for that, we’ll be using ServiceKey and later, Router-s which are special actors.
So, keeping all this in mind the code could look like this:
package workers
import org.apache.pekko.actor.typed.receptionist.ServiceKey
import workers.children.FileHandler.In.PrepareFile
import org.apache.pekko.actor.typed.{ActorRef, Behavior}
import org.apache.pekko.actor.typed.scaladsl.Behaviors
import serialization.CborSerializable
import workers.children.FileHandler
import scala.util._
object Worker {
// this enables Worker to be discovered by actors living on other nodes
val WorkerRouterKey = ServiceKey[Worker.StartExecution]("worker-router.StartExecution")
// simple model for grouping compiler, file extension and docker image for the programming language
private final case class LanguageSpecifics(
compiler: String,
extension: String,
dockerImage: String
)
// language specifics per language
private val languageSpecifics: Map[String, LanguageSpecifics] = Map(
"java" -> LanguageSpecifics(
compiler = "java",
extension = ".java",
dockerImage = "openjdk:17"
),
"python" -> LanguageSpecifics(
compiler = "python3",
extension = ".py",
dockerImage = "python"
),
"ruby" -> LanguageSpecifics(
compiler = "ruby",
extension = ".ruby",
dockerImage = "ruby"
),
"perl" -> LanguageSpecifics(
compiler = "perl",
extension = ".pl",
dockerImage = "perl"
),
"javascript" -> LanguageSpecifics(
compiler = "node",
extension = ".js",
dockerImage = "node"
),
"php" -> LanguageSpecifics(
compiler = "php",
extension = ".php",
dockerImage = "php"
)
)
// a parent type for modeling incoming messages
sealed trait In
final case class StartExecution(
code: String,
language: String,
replyTo: ActorRef[Worker.ExecutionResult]
) extends In with CborSerializable
// a parent type that models successful and failed executions
sealed trait ExecutionResult extends In {
def value: String
}
final case class ExecutionSucceeded(value: String) extends ExecutionResult with CborSerializable
final case class ExecutionFailed(value: String) extends ExecutionResult with CborSerializable
// constructor for creating Behavior[In]
def apply(workerRouter: Option[ActorRef[Worker.ExecutionResult]] = None): Behavior[In] = {
Behaviors.setup[In] { ctx =>
val self = ctx.self
Behaviors.receiveMessage[In] {
case msg @ StartExecution(code, lang, replyTo) =>
ctx.log.info(s"{} processing StartExecution", self)
languageSpecifics get lang match {
case Some(specifics) =>
val fileHandler = ctx.spawn(FileHandler(), s"file-handler")
ctx.log.info(s"{} sending PrepareFile to {}", self, fileHandler)
fileHandler ! FileHandler.In.PrepareFile(
name =
s"$lang${Random.nextInt}${specifics.extension}", // random number for avoiding file overwrite/shadowing
compiler = specifics.compiler,
dockerImage = specifics.dockerImage,
code = code,
replyTo = ctx.self
)
case None =>
val reason = s"unsupported language: $lang"
ctx.log.warn(s"{} failed execution due to: {}", self, reason)
replyTo ! Worker.ExecutionFailed(reason)
}
// register original requester
apply(workerRouter = Some(replyTo))
case msg @ ExecutionSucceeded(result) =>
ctx.log.info(s"{} sending ExecutionSucceeded to {}", self, workerRouter)
workerRouter.foreach(_ ! msg)
apply(workerRouter = None)
case msg @ ExecutionFailed(reason) =>
ctx.log.info(s"{} sending ExecutionFailed to {}", self, workerRouter)
workerRouter.foreach(_ ! msg)
apply(workerRouter = None)
}
}
}
}
So, Worker actor is designed to handle code execution requests for various programming languages. Here’s a concise breakdown:
ServiceKey:WorkerRouterKeyenables the actor to be discovered across different nodes.LanguageSpecifics: A case class and a map define compiler, file extension, and Docker image specifics for each supported programming language.Messages: TheIntrait and its implementations (StartExecution,ExecutionResult,ExecutionSucceeded,ExecutionFailed) model the messages the actor can handle.Behavior Setup: Theapplymethod sets up the actor’s behavior, processing incoming messages.- On
StartExecution, it logs the event, checks for language support, and spawns aFileHandleractor to handle file preparation. If the language isn’t supported, it responds withExecutionFailed. - On
ExecutionSucceededandExecutionFailed, it logs the outcome and sends the result back to the requester. ActorRef Management: Manages the original requester (workerRouterwhich will be defined later) to send back execution results.- The imports
import workers.children.FileHandler.In.PrepareFileandimport workers.children.FileHandlerwill be covered next, focusing on file preparation logic.
With this, we can move to FileHandler.
5.2 File Handler
FileHandler will be a local child actor for the Worker actor on the same worker node.
We’ve already seen PrepareFile message mentioned in Worker actor, but there must also be defined something like FilePrepared and FilePreparationFailed messages for covering both possible outcomes.
If file will be created, FileHandler should simply proceed with code execution, otherwise it should report immediately why the process failed.
With those expectations in mind, the code could look like the following:
package workers.children
import org.apache.pekko.actor.typed.{ActorRef, Terminated}
import org.apache.pekko.actor.typed.scaladsl.Behaviors
import org.apache.pekko.stream.scaladsl.{FileIO, Source}
import org.apache.pekko.util.ByteString
import workers.children.FileHandler.In.PrepareFile
import workers.Worker
import java.io.File
import java.nio.file.Path
import scala.concurrent.Future
import scala.util._
object FileHandler {
sealed trait In
object In {
case class PrepareFile(
name: String,
code: String,
compiler: String,
dockerImage: String,
replyTo: ActorRef[Worker.In]
) extends In
case class FilePrepared(
compiler: String,
file: File,
dockerImage: String,
replyTo: ActorRef[Worker.In]
) extends In
case class FilePreparationFailed(why: String, replyTo: ActorRef[Worker.In]) extends In
}
def apply() = Behaviors
.receive[In] { (ctx, msg) =>
import CodeExecutor.In._
import ctx.executionContext
import ctx.system
val self = ctx.self
ctx.log.info(s"{}: processing {}", self, msg)
msg match {
case In.PrepareFile(name, code, compiler, dockerImage, replyTo) =>
val filepath = s"/data/$name"
val asyncFile = for {
file <- Future(File(filepath))
_ <- Source
.single(code)
.map(ByteString.apply)
.runWith(FileIO.toPath(Path.of(filepath)))
} yield file
ctx.pipeToSelf(asyncFile) {
case Success(file) => In.FilePrepared(compiler, file, dockerImage, replyTo)
case Failure(why) => In.FilePreparationFailed(why.getMessage, replyTo)
}
Behaviors.same
case In.FilePrepared(compiler, file, dockerImage, replyTo) =>
val codeExecutor = ctx.spawn(CodeExecutor(), "code-executor")
// observe child for self-destruction
ctx.watch(codeExecutor)
ctx.log.info("{} prepared file, sending Execute to {}", self, codeExecutor)
codeExecutor ! Execute(compiler, file, dockerImage, replyTo)
Behaviors.same
case In.FilePreparationFailed(why, replyTo) =>
ctx.log.warn(
"{} failed during file preparation due to {}, sending ExecutionFailed to {}",
self,
why,
replyTo
)
replyTo ! Worker.ExecutionFailed(why)
Behaviors.stopped
}
}
.receiveSignal { case (ctx, Terminated(ref)) =>
ctx.log.info(s"{} is stopping because child actor: {} was stopped", ctx.self, ref)
Behaviors.stopped
}
}
The details:
Messages: TheInenum defines messages the actor can handle, includingPrepareFile,FilePrepared, andFilePreparationFailed.Behavior Setup: Theapplymethod sets up the actor’s behavior- On receiving
PrepareFile, it logs the event, attempts to write the code to a file asynchronously, and usespipeToSelfpattern to handle the result. - On
FilePrepared, it spawns aCodeExecutoractor to execute the code, watches it for termination, and sends anExecutemessage to the executor. - On
FilePreparationFailed, it logs the failure and sends anExecutionFailedmessage back to the requester.
And we arrived at the point where we can talk about the most important actor - CodeExecutor.
5.3 CodeExecutor
CodeExecutor actor will be a child of the local FileHandler actor on the same worker node.
The main responsibility for CodeExecutor is to execute code and return the output.
CodeExecutor actor is complex in nature due to the following reasons:
- code must be executed in a short-lived docker container
- code can cause memory issues
- code can cause cpu issues
- code can result in an accidental infinite loop
- code can be accumulating too much output
- and so on…
To tackle all this, we need to write a special logic and model the aforementioned concepts in a sensible way.
After struggling with those issues for a week or so, I managed to refine CodeExecutor iteratively, ending up with the following:
package workers.children
import org.apache.pekko.actor.typed.ActorRef
import org.apache.pekko.actor.typed.scaladsl.Behaviors
import org.apache.pekko.stream.IOResult
import org.apache.pekko.stream.scaladsl.{Sink, Source, StreamConverters}
import org.apache.pekko.util.ByteString
import workers.Worker
import java.io.{File, InputStream}
import scala.concurrent.{ExecutionContext, Future}
import scala.util.*
import scala.util.control.NoStackTrace
object CodeExecutor {
private val KiloByte = 1024 // 1024 bytes
private val MegaByte = KiloByte * KiloByte // 1,048,576 bytes
private val TwoMegabytes = 2 * MegaByte // 2,097,152 bytes
private val AdjustedMaxSizeInBytes =
(TwoMegabytes * 20) / 100 // 419,430 bytes, which is approx 409,6 KB or 0.4 MB
// max size of output when the code is run, if it exceeds the limit then we let the user know to reduce logs or printing
private val MaxOutputSize = AdjustedMaxSizeInBytes
enum In {
case Execute(compiler: String, file: File, dockerImage: String, replyTo: ActorRef[Worker.In])
case Executed(output: String, exitCode: Int, replyTo: ActorRef[Worker.In])
case ExecutionFailed(why: String, replyTo: ActorRef[Worker.In])
case ExecutionSucceeded(output: String, replyTo: ActorRef[Worker.In])
}
private case object TooLargeOutput extends Throwable with NoStackTrace {
override def getMessage: String =
"the code is generating too large output, try reducing logs or printing"
}
def apply() = Behaviors.receive[In] { (ctx, msg) =>
import Worker.*
import ctx.executionContext
import ctx.system
val self = ctx.self
msg match {
case In.Execute(compiler, file, dockerImage, replyTo) =>
ctx.log.info(s"{}: executing submitted code", self)
val asyncExecuted: Future[In.Executed] = for {
// timeout --signal=SIGKILL 2 docker run --rm --ulimit cpu=1 --memory=20m -v engine:/data -w /data rust rust /data/r.rust
ps <- run(
"timeout",
"--signal=SIGKILL",
"2", // 2 second timeout which sends SIGKILL if exceeded
"docker",
"run",
"--rm", // remove the container when it's done
"--ulimit", // set limits
"cpu=1", // 1 processor
"--memory=20m", // 20 M of memory
"-v", // bind volume
"engine:/data",
"-w", // set working directory to /data
"/data",
dockerImage,
compiler,
s"${file.getPath}"
)
// error and success channels as streams
(successSource, errorSource) = src(ps.getInputStream) -> src(ps.getErrorStream)
((success, error), exitCode) <- successSource
.runWith(readOutput) // join success, error and exitCode
.zip(errorSource.runWith(readOutput))
.zip(Future(ps.waitFor))
_ = Future(file.delete) // remove file in the background to free up the memory
} yield In.Executed(
output = if success.nonEmpty then success else error,
exitCode = exitCode,
replyTo = replyTo
)
ctx.pipeToSelf(asyncExecuted) {
case Success(executed) =>
ctx.log.info("{}: executed submitted code", self)
executed.exitCode match {
case 124 | 137 =>
In.ExecutionFailed(
"The process was aborted because it exceeded the timeout",
replyTo
)
case 139 =>
In.ExecutionFailed(
"The process was aborted because it exceeded the memory usage",
replyTo
)
case _ => In.ExecutionSucceeded(executed.output, replyTo)
}
case Failure(exception) =>
ctx.log.warn("{}: execution failed due to {}", self, exception.getMessage)
In.ExecutionFailed(exception.getMessage, replyTo)
}
Behaviors.same
case In.ExecutionSucceeded(output, replyTo) =>
ctx.log.info(s"{}: executed submitted code successfully", self)
replyTo ! Worker.ExecutionSucceeded(output)
Behaviors.stopped
case In.ExecutionFailed(why, replyTo) =>
ctx.log.warn(s"{}: execution failed due to {}", self, why)
replyTo ! Worker.ExecutionFailed(why)
Behaviors.stopped
}
}
private def readOutput(using ec: ExecutionContext): Sink[ByteString, Future[String]] =
Sink
.fold[String, ByteString]("")(_ + _.utf8String)
.mapMaterializedValue {
_.flatMap { str =>
if str.length > MaxOutputSize then Future failed TooLargeOutput
else Future successful str
}
}
private def src(stream: => InputStream): Source[ByteString, Future[IOResult]] =
StreamConverters.fromInputStream(() => stream)
private def run(commands: String*)(using ec: ExecutionContext) =
Future(sys.runtime.exec(commands.toArray))
}
Here it’s worth going into details since it’s the meat of the whole project.
Constants and Imports
- Constants:
KiloByte,MegaByte,TwoMegabytes: Constants for byte size calculations.AdjustedMaxSizeInBytes: Adjusted max size for output (approximately 409.6 KB).MaxOutputSize: Maximum allowed output size for the code execution.
- Imports:
- Imports various
PekkoandScalautilities for actor behavior, stream handling, and future operations.
- Imports various
Messages (In)
The In enum defines messages the actor can handle:
Execute: Message to execute a given file with a specific compiler and Docker image, and send the result to the specifiedActorRef.Executed: Message indicating the execution result, including output and exit code.ExecutionFailed: Message indicating the execution failed with a reason.ExecutionSucceeded: Message indicating the execution succeeded with the output.
Throwable for Large Output
A custom TooLargeOutput throwable is defined to handle scenarios where the code output exceeds the allowed size.
Behavior Definition
The apply method defines the actor’s behavior using Akka’s Behaviors.receive method:
In.Execute case
- Logging: Logs that code execution has started.
- Running Docker Command: Constructs and runs a Docker command with a 2-second timeout and memory limits.
- The Docker command binds the
enginevolume, sets the working directory to/data, and runs the provided compiler and file within the specified Docker image.
- The Docker command binds the
- Handling Streams: Handles both the standard and error streams from the Docker process.
- Reading Output: Reads the success and error streams and joins them with the exit code.
- Deleting File: Schedules the file for deletion to free up memory.
- Piping Result: Uses
ctx.pipeToSelfto handle the asynchronous execution result.- On success, checks the exit code and constructs appropriate messages (
ExecutionFailedfor specific exit codes orExecutionSucceeded). - On failure, logs the exception and constructs an
ExecutionFailedmessage.
- On success, checks the exit code and constructs appropriate messages (
In.ExecutionSucceeded case
- Logging: Logs successful execution.
- Replying: Sends an
ExecutionSucceededmessage to the requester. - Stopping Behavior: Stops the actor.
In.ExecutionFailed case
- Logging: Logs the failure reason.
- Replying: Sends an
ExecutionFailedmessage to the requester. - Stopping Behavior: Stops the actor.
Helper Methods
- readOutput: Defines a sink that reads ByteString input, converts it to a UTF-8 string, and checks if the output size exceeds the maximum allowed size.
- src: Creates a source from an input stream.
- run: Executes a command using
sys.runtime.execand returns a future of the process.
Detailed Workflow
- Execution Start: When the
Executemessage is received, the actor starts by logging the event. - Docker Command: It then constructs and runs the Docker command with specified limits.
- Stream Handling: Both the success and error streams from the Docker process are handled and read concurrently.
- Output Management: The output is read and checked against the maximum allowed size.
- File Deletion: The file is scheduled for deletion to free up memory.
- Result Handling: The result of the execution (success or failure) is handled and appropriate messages are constructed and sent to the requester.
- Actor Lifecycle: Depending on the message (
ExecutionSucceededorExecutionFailed), the actor stops itself after sending the reply.
This code ensures that code execution is managed efficiently within a controlled environment (Docker) and handles different outcomes (success, failure, timeouts, and memory limits) gracefully.
Now we can move on and talk about the clustering stuff.
6 - Pekko Cluster
In a distributed system, efficiently managing and coordinating tasks across multiple nodes is crucial for performance and scalability. Pekko, a robust toolkit for building highly concurrent, distributed, and resilient message-driven applications, offers powerful features for creating such systems. In this context, our code should implement a cluster system with distinct roles for worker and master nodes.
Components and Their Roles
- Cluster and Node Configuration:
- The cluster is initialized using
Cluster(ctx.system), and the node’s roles and configuration settings are obtained.
- The cluster is initialized using
- Worker Nodes:
- Worker Router:
- Each
workernode should initialize a pool ofworkeractors using aRound Robinrouting strategy. The pool size is configurable viatransformation.workers-per-node. - The worker router is registered with the
Receptionist, making it discoverable across the cluster.
- Each
- Worker Router:
- Master Node:
- Load Balancers:
- A pool of load balancers forwards execution tasks to the worker routers. The pool size is configurable via
transformation.load-balancer. - Each load balancer uses group routing to distribute tasks to remote worker routers.
- A pool of load balancers forwards execution tasks to the worker routers. The pool size is configurable via
- Load Balancers:
- HTTP Server:
- The
masternode sets up an HTTP server to accept task submissions. It listens on a configurable host and port. - Incoming tasks are forwarded to a randomly selected load balancer, which then distributes them to the worker nodes.
- The
Justification for the Components
- Efficiency and Scalability:
- Using a cluster setup with dedicated
workerandmasternodes allows for efficient task distribution and parallel processing. - The
Round Robinrouting ofworkeractors and load balancers ensures balanced workload distribution.
- Using a cluster setup with dedicated
- Dynamic Discovery and Registration:
- The
Receptionistenables dynamic discovery ofworkerrouters across the cluster, facilitating seamless scaling and fault tolerance.
- The
- Robust and Resilient Execution:
- Supervisory strategies for
workeractors enhance fault tolerance by restarting actors on failure. - The use of
askpatterns with timeouts ensures that task submissions are handled gracefully, even in the event of errors.
- Supervisory strategies for
- Configurability:
- Key parameters like the number of workers, load balancers, and server settings are configurable, allowing for flexibility and adaptability to different environments and workloads.
By leveraging these components and strategies, the cluster system can efficiently manage and distribute tasks across multiple nodes, providing a robust solution for distributed computing scenarios.
Keeping in mind all this, we could translate those expectations in code:
package cluster
import workers.Worker
import org.apache.pekko
import org.apache.pekko.actor.typed.receptionist.Receptionist
import org.apache.pekko.actor.typed.scaladsl.Behaviors
import org.apache.pekko.cluster.typed.Cluster
import pekko.actor.typed.{ActorSystem, Behavior}
import pekko.http.scaladsl.Http
import pekko.http.scaladsl.server.Directives.*
import org.apache.pekko.util.Timeout
import pekko.actor.typed.scaladsl.AskPattern.schedulerFromActorSystem
import pekko.actor.typed.scaladsl.AskPattern.Askable
import pekko.actor.typed.*
import pekko.actor.typed.scaladsl.*
import workers.Worker.*
import scala.concurrent.ExecutionContextExecutor
import scala.concurrent.duration.*
import scala.util.*
object ClusterSystem {
def apply(): Behavior[Nothing] = Behaviors.setup[Nothing] { ctx =>
import ctx.executionContext
val cluster = Cluster(ctx.system)
val node = cluster.selfMember
val cfg = ctx.system.settings.config
if (node hasRole "worker") {
val numberOfWorkers = Try(cfg.getInt("transformation.workers-per-node")).getOrElse(50)
// actor that sends StartExecution message to local Worker actors in a round robin fashion
val workerRouter = ctx.spawn(
behavior = Routers
.pool(numberOfWorkers) {
Behaviors
.supervise(Worker().narrow[StartExecution])
.onFailure(SupervisorStrategy.restart)
}
.withRoundRobinRouting(),
name = "worker-router"
)
// actors are registered to the ActorSystem receptionist using a special ServiceKey.
// All remote worker-routers will be registered to ClusterBootstrap actor system receptionist.
// When the "worker" node starts it registers the local worker-router to the Receptionist which is cluster-wide
// As a result "master" node can have access to remote worker-router and receive any updates about workers through worker-router
ctx.system.receptionist ! Receptionist.Register(Worker.WorkerRouterKey, workerRouter)
}
if (node hasRole "master") {
given system: ActorSystem[Nothing] = ctx.system
given ec: ExecutionContextExecutor = ctx.executionContext
given timeout: Timeout = Timeout(3.seconds)
val numberOfLoadBalancers = Try(cfg.getInt("transformation.load-balancer")).getOrElse(3)
// pool of load balancers that forward StartExecution message to the remote worker-router actors in a round robin fashion
val loadBalancers = (1 to numberOfLoadBalancers).map { n =>
ctx.spawn(
behavior = Routers
.group(Worker.WorkerRouterKey)
.withRoundRobinRouting(), // routes StartExecution message to the remote worker-router
name = s"load-balancer-$n"
)
}
}
val route =
pathPrefix("lang" / Segment) { lang =>
post {
entity(as[String]) { code =>
val loadBalancer = Random.shuffle(loadBalancers).head
val asyncResponse = loadBalancer
.ask[ExecutionResult](StartExecution(code, lang, _))
.map(_.value)
.recover(_ => "something went wrong")
complete(asyncResponse)
}
}
}
val host = Try(cfg.getString("http.host")).getOrElse("0.0.0.0")
val port = Try(cfg.getInt("http.port")).getOrElse(8080)
Http()
.newServerAt(host, port)
.bind(route)
ctx.log.info("Server is listening on {}:{}", host, port)
Behaviors.empty[Nothing]
}
}
The code above sets up an Pekko cluster with worker and master nodes.
- Receptionist: Registers the
workerrouters so they can be discovered cluster-wide. - HTTP Server: On the
masternode, it starts anHTTPserver to accept code execution requests. - Configuration: Reads settings for the number of
workers,load balancers, andHTTPserver details. - Worker Router: Each
workernode creates a pool of ``worker actors usinground-robinrouting. - Load-Balancer: The
masternode createsload balancersto forward tasks toworkerrouters.
Algorithm for Code Execution:
HTTP POSTrequest with code is received.- A random
load balancerforwards the request to aworkerrouter. - The
workerrouter assigns the task to a worker actor, which executes the code and returns the result.
With that we finish the part which is concerned with code.
Let’s move on to the final part of the project - running it all locally.
7. Local Deployment
To deploy the project locally we should simply run ./deploy.sh and wait to see the logs from the worker and master nodes.
For the details, please view the README of the original project.
The only requirement is to have the docker engine installed locally.
8. Simulator
To get the better feeling of how the app performs under a certain load I decided to write the Simulator.scala which simulates the behaviour of the concurrent users.
Simulator.scala must be run as a separate process, assuming that the execution engine is already started and is ready to accept requests.
To some extent, testing the load on the locally deployed cluster may not be the best idea since all the nodes are using the shared resources of the single laptop, but I had to give it a try.
The goal of the simulator is to perform aggregate the statistics of things such as:
- total requests in a minute
- average response time
- error count
- response time percentiles: p50, p90, p99
With those expectations in mind, Simulator.scala could look like the following:
package simulator
import com.typesafe.config.ConfigFactory
import org.apache.pekko.actor.{ActorSystem, Cancellable}
import org.apache.pekko.http.scaladsl.Http
import org.apache.pekko.http.scaladsl.model.*
import org.apache.pekko.stream.scaladsl.{Flow, Keep, Sink, Source}
import org.apache.pekko.util.ByteString
import org.apache.pekko.{Done, NotUsed}
import java.time.Instant
import java.time.temporal.ChronoUnit
import java.util.concurrent.atomic.{AtomicInteger, AtomicLong}
import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
import scala.concurrent.duration.*
import scala.concurrent.{ExecutionContextExecutor, Future}
import scala.util.Random.shuffle
object Simulator extends App {
val actorSystem = "SimulatorSystem"
given system: ActorSystem = ActorSystem(actorSystem, ConfigFactory.load("simulator.conf"))
given ec: ExecutionContextExecutor = system.classicSystem.dispatcher
val http = Http(system)
val requestCount = AtomicInteger(0)
val responseTimes = AtomicLong(0)
val responseTimeDetails = mutable.ArrayBuffer.empty[Long]
val errors = AtomicInteger(0)
def stream(name: String, interval: FiniteDuration) = {
// generate random code per 125 milliseconds
val generateRandomCode: Source[Code, Cancellable] = Source
.tick(0.seconds, interval, NotUsed)
.map(_ => Code.random)
// send http request to remote code execution engine
val sendHttpRequest: Flow[Code, (Instant, Instant, String, Code), NotUsed] = Flow[Code]
.mapAsync(100) { code =>
val request = HttpRequest(
method = HttpMethods.POST,
uri = "http://localhost:8080/lang/python",
entity = HttpEntity(ContentTypes.`application/json`, ByteString(code.value))
)
val (now, requestId) = (Instant.now(), randomId())
println(s"[$name]: sending Request($requestId, $code) at $now")
http
.singleRequest(request)
.map { response =>
val end = Instant.now()
val duration = ChronoUnit.MILLIS.between(now, end)
response.discardEntityBytes()
requestCount.incrementAndGet()
responseTimes.addAndGet(duration)
responseTimeDetails += duration
(now, end, requestId, code)
}
.recover {
case ex =>
println(s"[$name] failed: ${ex.getMessage}")
errors.incrementAndGet()
(now, Instant.now(), requestId, code)
}
}
// display the http response time
val displayResponseTime: Sink[(Instant, Instant, String, Code), Future[Done]] =
Sink.foreach { (start, end, requestId, code) =>
val duration = ChronoUnit.MILLIS.between(start, end)
println(
s"[$name]: received response for Request($requestId, $code) in $duration millis at: $end"
)
}
// join the stream
generateRandomCode
.via(sendHttpRequest)
.toMat(displayResponseTime)(Keep.right)
}
// run the stream
stream("simulator", 160.millis)
.run()
system.scheduler.scheduleWithFixedDelay(60.seconds, 60.seconds) { () =>
val count = requestCount.getAndSet(0)
val totalResponseTime = responseTimes.getAndSet(0)
val averageResponseTime = if (count > 0) totalResponseTime / count else 0
val errorCount = errors.getAndSet(0)
val p50 = percentile(responseTimeDetails, 50)
val p90 = percentile(responseTimeDetails, 90)
val p99 = percentile(responseTimeDetails, 99)
println("-" * 50)
println(s"Requests in last minute: $count")
println(s"Average response time: $averageResponseTime ms")
println(s"Error count: $errorCount")
println(s"Response time percentiles: p50=$p50 ms, p90=$p90 ms, p99=$p99 ms")
println("-" * 50)
responseTimeDetails.clear()
}
private def randomId(): String =
java.util.UUID
.randomUUID()
.toString
.replace("-", "")
.substring(1, 10)
private def percentile(data: ArrayBuffer[Long], p: Double): Long =
if data.isEmpty then 0
else {
val sortedData = data.sorted
val k = (sortedData.length * (p / 100.0)).ceil.toInt - 1
sortedData(k)
}
enum Code(val value: String) {
case MemoryIntensive extends Code(Python.MemoryIntensive)
case CPUIntensive extends Code(Python.CPUIntensive)
case Random extends Code(Python.Random)
case Simple extends Code(Python.Simple)
case Instant extends Code(Python.Instant)
}
object Code {
def random: Code = shuffle(Code.values).head
}
object Python {
val MemoryIntensive =
"""
|def memory_intensive_task(size_mb):
| # Create a list of integers to consume memory
| data = [0] * (size_mb * 1024 * 1024) # Each element takes 8 bytes on a 64-bit system
| return data
|print(memory_intensive_task(2)) # Allocate 10 MB of memory
|""".stripMargin
val CPUIntensive =
"""
|def cpu_intensive_task(n):
| result = 0
| for i in range(n):
| result += i * i
| return result
|print(cpu_intensive_task(50))
|""".stripMargin
val Random =
"""import random
|
|# Initialize the stop variable to False
|stop = False
|
|while not stop:
| # Generate a random number between 1 and 100
| random_number = random.randint(1, 1000)
| print(f"Generated number: {random_number}")
|
| # Check if the generated number is greater than 80
| if random_number == 1000:
| stop = True
|
|print("Found a number greater than 80. Exiting loop.")
|""".stripMargin
val Simple =
"""
|for i in range(1, 500):
| print("number: " + str(i))
|""".stripMargin
val Instant = "print('hello world')"
}
}
Here are the important points:
-
Imports: The code uses Apache Pekko for actor-based concurrency, HTTP client, and stream processing. It also imports utilities for handling concurrency and mutable collections.
- Actor System Setup:
- The actor system (
SimulatorSystem) and execution context are initialized with a configuration file (simulator.conf).
- The actor system (
- Metrics:
- Atomic variables are used to track request counts, response times, response details, and errors.
- Stream Definition:
- A stream is defined to generate random codes and send HTTP POST requests to a remote server at regular intervals.
generateRandomCode: Generates a random code every specified interval (e.g., 160 milliseconds).sendHttpRequest: Sends the generated code as an HTTP POST request and records the response time.displayResponseTime: Displays the response time for each request.
- Stream Execution:
- The stream is run with the name “simulator” and an interval of 160 milliseconds.
- Metrics Logging:
- Every 60 seconds, the code logs metrics such as the number of requests, average response time, error count, and response time percentiles (p50, p90, p99).
- Utility Methods:
randomId: Generates a random request ID.percentile: Calculates response time percentiles from recorded data.
- Enum and Object Definitions:
CodeEnum: Defines various types of codes (e.g.,MemoryIntensive,CPUIntensive).PythonObject: Contains Python code snippets for different tasks.
This setup continuously sends HTTP requests, tracks metrics, and periodically logs performance data.
Please, run it and share the performance details with me, feel free to play with numbers as well :)
9. Conclusion
In this blog post, we’ve explored the journey of building a robust, scalable, and efficient remote code execution engine using Scala 3 and Apache Pekko. Our system leverages a master-worker architecture, with one master node and three worker nodes to distribute and manage code execution tasks across a cluster. Let’s recap the key components and features of our solution.
Key Components and Features
- Cluster Awareness with Receptionist and Router:
- By using
ReceptionistandRouter, we ensured our system is cluster-aware, allowing dynamic scaling and efficient task distribution among worker nodes.
- By using
- Actors for Task Management:
Worker: Coordinates tasks on the worker nodes, ensuring seamless processing and communication with the master node.FileHandler: Manages file preparation required for code execution.CodeExecutor: Executes the code snippets in a sibling docker container and collects the output.
- Docker-out-of-Docker (DooD) Approach:
- Each worker node runs as a Docker container, and within these containers, we utilize the DooD approach to execute sibling containers. This method provides isolation and security, ensuring each code execution happens in a controlled and disposable environment.
- Resource Management and Security:
- We’ve set stringent resource limits (CPU, RAM) and a 2-second timeout for code execution. These measures protect the system from malicious code, such as infinite loops, ensuring stability and security.
- Support for Multiple Languages:
- Our engine supports six programming languages, demonstrating its versatility and adaptability to various use cases.
Scalability and Efficiency
The design choices made in this project ensure that our remote code execution engine can scale efficiently with the demands. By distributing the workload across multiple worker nodes and dynamically managing these nodes using cluster-aware techniques, we can handle a large number of concurrent code execution requests without compromising performance.
Final Thoughts
Building this distributed system with Scala 3 and Apache Pekko has been an enlightening experience. We’ve harnessed the power of actor-based concurrency, cluster management, and containerization to create a resilient and secure remote code execution engine. This project exemplifies how modern technologies can be integrated to solve complex problems in a scalable and efficient manner.
Whether you’re looking to implement a similar system or seeking insights into distributed computing with Scala and Pekko, we hope this blog post has provided valuable knowledge and inspiration.